シナプスネットワーク課の杉原と申します。
今回は正規表現についてご紹介したいと思います。
正規表現とは
正規表現とは、メタ文字と呼ばれる記号を組み合わせた表現を使って、一定条件の文字列を照合する方法です。
代表的なメタ文字一覧
| メタ文字 | 機能 | 備考 |
|---|---|---|
| ^ | 論理行の行頭 | |
| $ | 論理行の行末 | |
| ? | ?の前の文字が0個または1個 | |
| * | *の前の文字が0個以上 | |
| + | +の前の文字が1個以上 | |
| {min,max} | {min,max}の前の文字の最大数・最少数 | |
| . | 任意の文字 | |
| [ ] | [ ]内の文字のどれか | |
| [^ ] | [ ]内でない文字のどれか | |
| \ | 後ろのメタ文字をエスケープする | |
| | | 「条件A|条件B」で「条件Aまたは条件B」 | 拡張正規表現のみ |
| & | 「条件A&条件B」で「条件Aかつ条件B」 | 拡張正規表現のみ |
主な使いどころとして以下のケースがあげられます。
- ログの解析で特定の文字列を抽出する
- プログラム上での検索・置換・バリデーションに役立つ
- テキストエディタで文字列の検索・置換を効率化することできる
ここまで読んでもよくわからないと思うので、実際に使われるケースを交えながら、正規表現について説明したいと思います。
その前に、ひとつ注意しなければならないことがあります。
正規表現の種類・方言について
正規表現は改良が重ねられ、書き方の規格が2度にわたり更新されました。
正規表現のバージョンを大きく3種類に分けると
- 元来使われていた単純正規表現(SRE, Simple Regular Expression)
- 1度目の更新版である基本正規表現(BRE, Basic Regular Expression)
- 2度目の更新版である拡張正規表現(ERE, Expanded Regular Expression)
と呼ばれ、区別されています。
また、実行されるOSのシェルやプログラミング言語、テキストエディタによって、微妙に書き方が異なる場合があります。
この違いのことを私達が話す言葉に例えて方言と呼びます。
このように実行環境によって正規表現の書き方に差異が出てくるので、書いた処理が期待通りにならないときは各環境の公式ドキュメントを確認することを推奨します。
正規表現のユースケース
それでは実際に正規表現が使われる事例を見てみましょう。
特定の時間のログを取得したい
LinuxでPostfix(MTA: Mail Transfer Agent)の本日の8時から13時までの送信ログを見たい場合を考えます。
postfixのメールログ/var/log/maillogのフォーマットは以下の通りになっています。
Dec 22 08:30:57 po postfix-auth/qmgr[5000]: AAAAAAAAAAA: removed Dec 22 08:30:56 po postfix-auth/smtpd[50000]: AAAAAAAAAAA: client=example.com[192.0.2.0], sasl_method=LOGIN, sasl_username=dummy@example.com Dec 22 08:30:56 po postfix-auth/cleanup[50000]: AAAAAAAAAAA: message-id=<aaaaaaaaaaaaaaaaaaaaaaaaaaaa$@example.com> Dec 22 08:30:57 po postfix-auth/qmgr[5000]: AAAAAAAAAAA: from=<dummy@example.com>, size=12345, nrcpt=1 (queue active) Dec 22 08:30:57 po postfix-auth/smtp[500]: AAAAAAAAAAA: to=<yummy@example.com>, relay=mx.example.com[198.51.100.0]:25, delay=0.8, delays=0.7/0/0/0.1, dsn=2.0.0, status=sent (250 Message accepted.)
※ドメイン・IPアドレスはダミーです。[RFC2606] 、[RFC6890]を参照のこと。
cat /var/log/maillogのコマンドを実行することで、メールログを全て読み込みます。
テキストを画面に出力するコマンドの後に|と文字列を操作するコマンドを続けて書いて実行すると、テキストを抽出・加工した状態で出力することができます。
これをパイプといいます。
UNIX系 OSで正規表現の文字列をが含まれる行だけを抽出するコマンドは、基本正規表現用の grep "[文字列・正規表現]" もしくは拡張正規表現用の egrep "[文字列・正規表現] です。
cat /var/log/maillog | grep "aaa" というコマンドを実行すると、/var/log/maillogの全文からaaaという文字列が含まれる行だけを表示します。
cat /var/log/maillog | grep "^aaa" というコマンドの場合は、論理行の行頭を意味するメタ文字^が含まれているので、
/var/log/maillogの全文のうち、aaaという文字列から始まる行だけを抜き出して表示します。
それでは、8時から13時までのログを正規表現を使って抽出する方法について検討します。
ログは必ずDec 22から始まり、その直後に時刻が記述されていることに注目すると、以下の文字列から始まる行だけを抜き出せば、8時から13時までのログを抜き出すことになりますね。
Dec 22 08 ... Dec 22 09 ... Dec 22 10 ... Dec 22 11 ... Dec 22 12 ... Dec 22 13 ...
ここで論理行の行頭を表すメタ文字^と複数の文字のうちどれかが入ることを意味する[]を使います。
[]の中にハイフンを使うと連続した文字を指定することになり、[0-9]は[0123456789]と同じ意味で、「数字の0~9のいずれか」を表します。
`^Dec 22 0[89]で8時・9時、^Dec 22 1[0-3]で10時から13時までを指定できます。
ここで求めるのは8時から13時までなので、条件の「または」を意味する|でつなげます。
cat /var/log/maillog | grep "^Dec 22 0[89]|^Dec 22 1[0-3]"
これを実行するとうまくいきません。
なぜかというと、「または」を意味する|は拡張正規表現でしか使えないからです。
よって、拡張正規表現に対応したegrepもしくはgrep -Eを使います。
cat /var/log/maillog | egrep "^Dec 22 0[89]|^Dec 22 1[0-3]"
cat /var/log/maillog | grep -E "^Dec 22 0[89]|^Dec 22 1[0-3]"
実行結果は両方とも8時~13時のログが表示されるはずです。
実務では、大量のログが一気に表示されるので、
cat /var/log/maillog | egrep "^Dec 22 0[89]|^Dec 22 1[0-3]" | more
という風に最後に| moreをつけて、スペースキーを押した分だけスクロールして見ることができるようにします。
プログラムで文字列がメールアドレスかどうかを判定する
先程はLinuxのログ解析での正規表現の使用方法を紹介しましたが、今度はWebプログラムで正規表現を使う場面を紹介します。
よく皆さんはWebサービスのログインやユーザー登録のときに、メールアドレスをフォームの中に入力することがあるかと思います。

このメールアドレスの入力欄に電話番号や住所のような全く関係のない文字列が入ってはいけないように、入力された文字列がメールアドレスの要件をみたす文字列かどうかを判断する方法を実装します。
今回考えるメールアドレスの構造を[ローカル部]@[ドメイン部]としたとき、要件は以下の通りとします。
ローカル部の最初に使える文字は半角英字大文字・小文字・半角数字
ローカル部の2文字目以降に使える文字は半角英字大文字・小文字・半角数字と記号「_」「.」「-」「+」で、2文字目以降はなくてもよい。
ドメイン部の最初に使える文字は半角英字大文字・小文字・半角数字と記号「-」
ドメイン部の2文字目以降に使える文字は半角英字大文字・小文字・半角数字と記号「-」。ただし、間に「.」を最低1つ入れる。「.」は最大で3つまで許容する。(例: example.com , kagoshima.example.ne.jp )
それぞれ正規表現での検討します。
1. ローカル部の最初に使える文字は半角英字大文字・小文字・半角数字
まず、前回半角数字の0~9は[0-9]と表現できると説明しましたが、半角英字でも[A-Za-z]という風に同様のことができます。
意味は半角アルファベットの大文字のA~Z・小文字のa~zのいずれかの文字となります。
よって、1.の要件を正規表現で表記すると以下の通りになります。
^[A-Za-z0-9]
2. ローカル部の2文字目以降に使える文字は半角英字大文字・小文字・半角数字と記号「_」「.」「-」「+」で、2文字目以降はなくてもよい。
今回は1.のケースに「_」「.」「-」「+」を加えたものとなります。
ここで注意しなければならないのが、正規表現では「.」はあらゆる文字種1文字分、「-」は範囲、「+」は前の文字1つ以上連続を表すメタ文字です。
今回はあくまでメールアドレスの中の文字列としての「.」「-」「+」記号を判別したいので、これらの文字の前にエスケープ用のメタ文字\を追記します。
[A-Za-z0-9_\.\-\+]
2文字目はなくてもいい。もしくは、半角英字大文字・小文字・半角数字と記号「_」「.」「-」「+」のいずれかが1文字以上つづくので[A-Za-z0-9_\.\-\+]の後に、0字以上の繰り返しを意味する*を添えます。
[A-Za-z0-9_\.\-\+]*
これを1.で作ったものと合わせます。
^[A-Za-z0-9][A-Za-z0-9_\.\-\+]*
これでローカル部が完成したので、最後に@を加えます。
^[A-Za-z0-9][A-Za-z0-9_\.\-\+]*@
次はドメイン部の正規表現について検討します。
3. ドメイン部の最初に使える文字は半角英字大文字・小文字・半角数字と記号「-」
2.と同じ考え方で[A-Za-z0-9\-]とします。
ここまでをまとめると、以下のようになります。
^[A-Za-z0-9][A-Za-z0-9_\.\-]*@[A-Za-z0-9\-]
4. ドメイン部の2文字目以降に使える文字は半角英字大文字・小文字・半角数字と記号「-」。
- ただし、間に「.」を最低1つ入れる。
- 「.」は最大で3つまで許容する。(例: example.com , example.ne.jp , kagoshima.example.ne.jp )
- 「.」は連続してはならない。(「..」NG )
kagoshima.example.ne.jpの赤字部分が4.に相当しますが、この部分をドットで区切ってみると
- [半角英字大文字・小文字・英数・ハイフンのいずれかの文字]が1つ以上
- ドット
- [半角英字大文字・小文字・英数・ハイフンのいずれかの文字]が1つ以上
- ドット
- [半角英字大文字・小文字・英数・ハイフンのいずれかの文字]が1つ以上
- ドット
- [半角英字大文字・小文字・英数・ハイフンのいずれかの文字]が1つ以上
- 行末
となります。
これを正規表現で表記すると
[A-Za-z0-9\-]+\.[A-Za-z0-9\-]+\.[A-Za-z0-9\-]+\.[A-Za-z0-9\-]+$
と表すことができます。
しかしこれでは「example.com」や「example.ne.jp」のように、ドットの数が1つもしくは2つだけの場合はマッチしなくなります。
そこで、その直前の文字が0個または1個のときにマッチすることをを示すメタ文字?を2.のドットと4.のドットの直後に置きます。これにより、両者のドットがあってもなくてもドメインがマッチする扱いにします。
[A-Za-z0-9\-]+\.?[A-Za-z0-9\-]+\.?[A-Za-z0-9\-]+\.[A-Za-z0-9\-]+$
これで「example.com」「example.ne.jp」「kagoshima.example.ne.jp」のドットの数が1~3個全てのパターンのドメインとマッチするようになりました。
1.~4.までをまとめると以下の通りになります。
^[A-Za-z0-9][A-Za-z0-9_\.\-\+]*@[A-Za-z0-9\-][A-Za-z0-9\-]+\.?[A-Za-z0-9\-]+\.?[A-Za-z0-9\-]+\.[A-Za-z0-9\-]+$
これで、メールアドレスの文字列を表現する正規表現の完成です。
さて、それではJavaScriptで文字列を正規表現で判定する方法を簡潔に説明します。
まず、変数regに先程書いた正規表現を代入します。正規表現の前後両端には/を書くのを忘れないでください。
const reg = /^[A-Za-z0-9][A-Za-z0-9_\.\-\+]*@[A-Za-z0-9\-][A-Za-z0-9\-\.]+\.?[A-Za-z0-9\-\.]+\.?[A-Za-z0-9\-\.]+\.[A-Za-z0-9\-]+$/;
その後、正規表現入りの変数regについて、メソッドチェーンtest(str)を使います。
reg.test(email)
testメソッドは引数strの文字列について変数regの正規表現を満たしていればtrueの値を、満たしていなければfalseの値をを返します。
今回は三項演算子で、trueのときは適合の文字列を、falseのときは不適合の文字列を返すメソッドchkAddressを作りました。
// main.js
function chkAddress(email){
const reg = /^[A-Za-z0-9][A-Za-z0-9_\.\-\+]*@[A-Za-z0-9\-][A-Za-z0-9\-]+\.?[A-Za-z0-9\-]+\.?[A-Za-z0-9\-]+\.[A-Za-z0-9\-]+$/;
return reg.test(email) ? "適合" : "不適合"
}
console.log(chkAddress('sugihara@example.com'));
console.log(chkAddress('sugihara@exam-ple.com'));
console.log(chkAddress('sugi-hara@example.com'));
console.log(chkAddress('sugi-hara@example.ne.jp'));
console.log(chkAddress('sugi-hara@kagoshima.example.ne.jp'));
console.log(chkAddress('sugi-hara@examplecom'));
console.log(chkAddress('.sugi-hara@example.com'));
console.log(chkAddress('aaaaa'));
console.log(chkAddress('000-1234-5678'));
出力結果 --------------------------------------------------------------- 適合 適合 適合 適合 適合 不適合 不適合 不適合 不適合
※paiza.IOにて実行
実際のRFC5321やRFC5322の定義では、メールアドレスにおいて上記の「+」「-」「.」「_」以外にも多数の記号が許容されている他、非常に複雑な要件を含んでいます。
この要件を可能な限り満たす正規表現を有志の方がまとめてくださったので、こちらを御覧ください。
キャプチャ機能を使う
次に正規表現のキャプチャについて説明します。キャプチャはテキストエディタでの置換処理と組み合わせると便利な機能です。 今回は Visual Studio Code (以下、VSCode)で説明しますが、サクラエディタや秀丸エディタなど他のテキストエディタにも同様の機能があります。
小説の地の文の文頭に全角空白を入れる
ginga.txtというファイル名のテキストファイルを用意します。内容は以下の通りです。
「ジョバンニさん。あなたはわかっているのでしょう」 ジョバンニは勢いきおいよく立ちあがりましたが、立ってみるともうはっきりとそれを答えることができないのでした。ザネリが前の席せきからふりかえって、ジョバンニを見てくすっとわらいました。ジョバンニはもうどぎまぎしてまっ赤になってしまいました。先生がまた言いいました。 「大きな望遠鏡ぼうえんきょうで銀河ぎんがをよっく調しらべると銀河ぎんがはだいたい何でしょう」 やっぱり星だとジョバンニは思いましたが、こんどもすぐに答えることができませんでした。 先生はしばらく困こまったようすでしたが、眼めをカムパネルラの方へ向むけて、 「ではカムパネルラさん」と名指なざしました。 するとあんなに元気に手をあげたカムパネルラが、やはりもじもじ立ち上がったままやはり答えができませんでした。 先生は意外いがいなようにしばらくじっとカムパネルラを見ていましたが、急いそいで、 「では、よし」と言いいながら、自分で星図を指さしました。
青空文庫 宮沢賢治『銀河鉄道の夜』より リンク
この小説のテキストファイルに行番号(論理行)をふると以下の通りになります。
01 |「ジョバンニさん。あなたはわかっているのでしょう」 02 |ジョバンニは勢いきおいよく立ちあがりましたが、立ってみるともうはっきりとそれを答えることができないのでした。ザネリが前の席せきからふりかえって、ジョバンニを見てくすっとわらいました。ジョバンニはもうどぎまぎしてまっ赤になってしまいました。先生がまた言いいました。 03 |「大きな望遠鏡ぼうえんきょうで銀河ぎんがをよっく調しらべると銀河ぎんがはだいたい何でしょう」 04 |やっぱり星だとジョバンニは思いましたが、こんどもすぐに答えることができませんでした。 05 |先生はしばらく困こまったようすでしたが、眼めをカムパネルラの方へ向むけて、 06 |「ではカムパネルラさん」と名指なざしました。 07 |するとあんなに元気に手をあげたカムパネルラが、やはりもじもじ立ち上がったままやはり答えができませんでした。 08 |先生は意外いがいなようにしばらくじっとカムパネルラを見ていましたが、急いそいで、 09 |「では、よし」と言いいながら、自分で星図を指さしました。
日本語で書かれた小説は通常、「から始まらない行の頭には全角空白を入れます。
上の文章なら2、4、5、7、8行目が全角空白から始まる必要があります。
9行しか無いこのファイルならひとつひとつ手打ちで全角空白を入力してもいいですが、これが何百、何千行もあるファイルとなると非常に骨の折れる作業になります。
では、「から始まらない行の頭に全角空白を入れるにはどうすればいいでしょうか?
テキストエディタと正規表現の出番です。
「からはじまらない行を正規表現で指定して、行頭に空白を入れる処理を考えます。
1. .+で文字列1行分を意味する
これまで.は何かしらの任意の文字と説明してきましたが、厳密にいうと改行コード以外の任意の文字です。
よって、.+と書いた場合、改行コード以外の何かしらの文字が1文字以上連続する文字列のまとまり、すなわちテキストの1行分という意味になります。
2. [^]で指定したの文字以外のいずれかの文字を意味する
正規表現では[^ ]で[^と]に囲まれた文字以外のいずれかの文字という意味になります。
[^0-9]なら「半角数字以外の文字列」、[^A-Za-z]なら「半角アルファベット以外の文字列」という意味です。
「ではない文字であれば、[^「]となります。
先程、1. の表記法と組み合わせると、『「から始まらない行』、正規表現の要件にあてはめやすい形でいうと『行頭が「以外の文字で始まる行』は^[^「].+と表記できます。
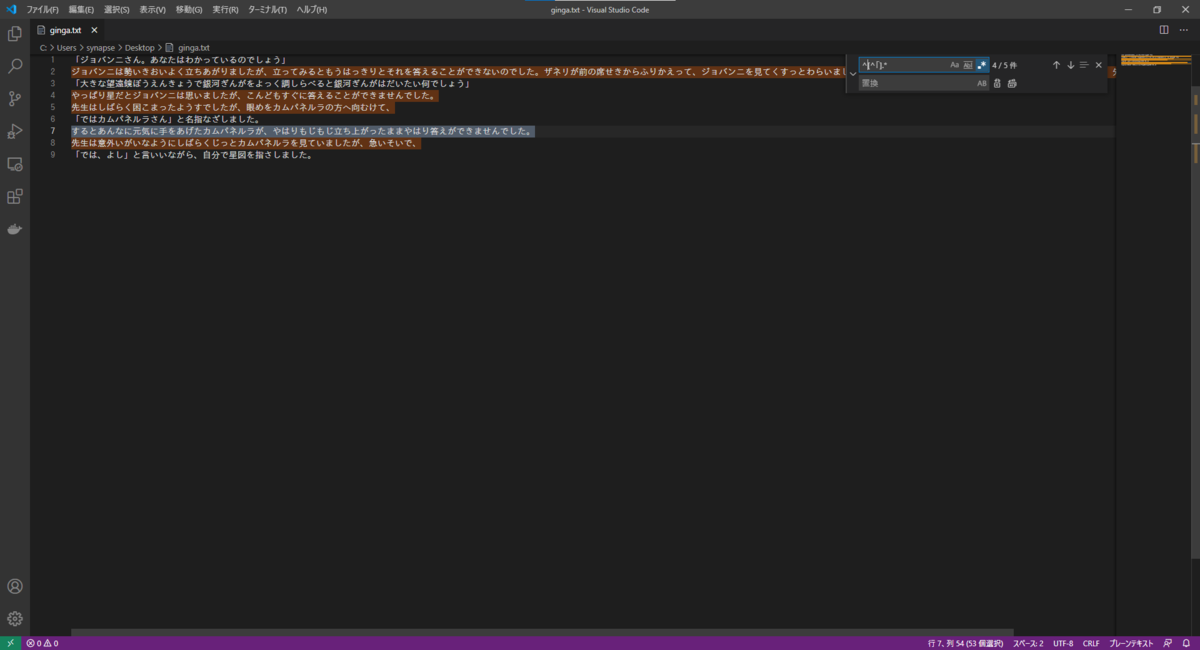
それではVS Codeでginga.txtを開き、Windowsの場合は Ctrl + H で、Macの場合は Command + H で置換画面を開きます。
その後、.*マークのアイコンをクリックし、正規表現を有効にします。

検索枠に^[^「].+を入力すると、以下のようにヒットします。
ただ、このまま置換しても、対象の行が消えるだけです。
ここでキャプチャを使います。キャプチャとは正規表現を()で囲んで、かつ、置換後の文字列に$1などの文字を入れると、置換後の文字列に()で囲まれた部分の文字列が残るという機能です。
今回、一行全体を残したいので(^[^「].+)と書きます。そして、置換後の文字列には $1と書きます。
| 置換前 | 置換後 |
|---|---|
| (^[^「].+) | $1 |

全部置換を実行すると、先程選択されていた行の頭に全角空白が追加されているはずです。

「ジョバンニさん。あなたはわかっているのでしょう」 ジョバンニは勢いきおいよく立ちあがりましたが、立ってみるともうはっきりとそれを答えることができないのでした。ザネリが前の席せきからふりかえって、ジョバンニを見てくすっとわらいました。ジョバンニはもうどぎまぎしてまっ赤になってしまいました。先生がまた言いいました。 「大きな望遠鏡ぼうえんきょうで銀河ぎんがをよっく調しらべると銀河ぎんがはだいたい何でしょう」 やっぱり星だとジョバンニは思いましたが、こんどもすぐに答えることができませんでした。 先生はしばらく困こまったようすでしたが、眼めをカムパネルラの方へ向むけて、 「ではカムパネルラさん」と名指なざしました。 するとあんなに元気に手をあげたカムパネルラが、やはりもじもじ立ち上がったままやはり答えができませんでした。 先生は意外いがいなようにしばらくじっとカムパネルラを見ていましたが、急いそいで、 「では、よし」と言いいながら、自分で星図を指さしました。
時刻フォーマットを変換する
前回キャプチャで$1という文字をつかいました。
勘のいい人は気づいたかと思いますが、キャプチャは$1、$2、$3……と続けて複数使うこともできます。
今回もVS Codeを使います。time.txtを用意します。内容は以下の通り。
01:12:11 09:12:30 10:02:28 11:07:28 12:43:08 15:27:02 23:51:37
現在time.txtには時刻がhh:mm:ss表記で書かれていますが、こちらを○時○分○秒という表記に置換します。
{n}で直前の文字をn回繰り返すという意味なので、hh:mm:ss表記の時刻は正規表現では[0-9]{2}:[0-9]{2}:[0-9]{2}と表記できます。
実は、0~9の任意の数字は\dとも書けます。今回は、検索枠に\d{2}:\d{2}:\d{2}と入力してみます。
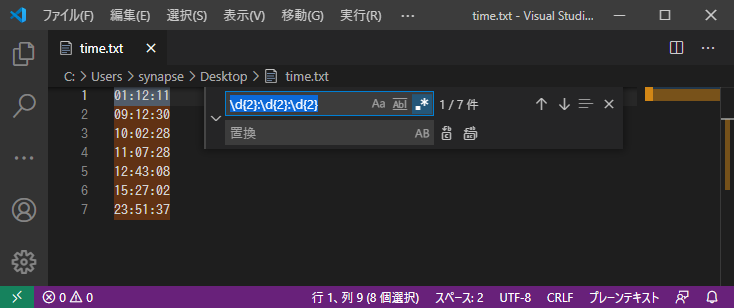
今、01:12:11を01時12分11秒に変換したいので、時・分・秒を括弧でくくり、検索枠の文字列を(\d{2}):(\d{2}):(\d{2})と書き換えます。
置換後の文字列は、1番目の括弧内が$1、2番目の括弧内が$2、3番目の括弧内が$3に入るので、置換後の文字は$1時$2分$3秒と入力します。
| 置換前 | 置換後 |
|---|---|
| (\d{2}):(\d{2}):(\d{2}) | $1時$2分$3秒 |
01時12分11秒 09時12分30秒 10時02分28秒 11時07分28秒 12時43分08秒 15時27分02秒 23時51分37秒
成功しました。
ただ、「01時」のように日本語の時刻表記で2桁目の0詰めを行うと気持ち悪いので、0ではじまる時間について普通の0詰めでない表記に変換します。
| 置換前 | 置換後 |
|---|---|
| 0(\d) | $1 |
こうするとキャプチャされた任意の数字\dが置換後も残りますが、0は残りません。
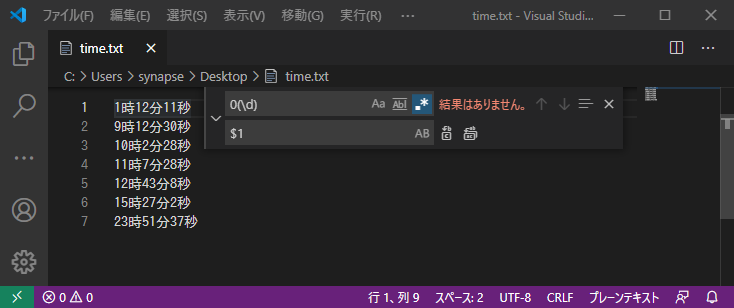
1時12分11秒 9時12分30秒 10時2分28秒 11時7分28秒 12時43分8秒 15時27分2秒 23時51分37秒
きれいになりました。
正規表現の苦手分野
ここまで正規表現の便利な活用法を紹介しましたが、そんな正規表現でも対処できないケースがあるのでご紹介します。
複数の種類の文字の置換
全角・半角の置換(例:abcdefgをabcdefgに置換)やアラビア数字・漢数字の置換(123456789を一二三四五六七八九)のように複数の種類の文字を一対一の関係で一括変換することはできません。
このような場合は、文字列の文字コードを一文字ずつ読み取って置き換えていくプログラムを用意する必要があります。
入れ子構造になっている文字列
数式や条件分岐文、HTMLタグ、JSONファイルなど、複数の括弧が入れ子構造になっている文字列では、うまくいかないことがあります。 以下の数式を例に取ってみましょう。
a = ( ( 1000 + 100 ) * 10 / 2 + ( 200 + ( 10 + 30 ) / 2 ) * 100 ) + ( 3 + 5 ) * 20
この数式で、以下の処理を実行したいと思います。
括弧の中の括弧の式の部分(ここでは
( 1000 + 100 )と( 200 + ( 10 + 30 ) / 2 ) * 100 )を抽出して、両端の括弧の種類を()から{}に置換括弧の中の括弧の中の括弧の式の部分(ここで
( 10 + 30 ))を抽出して、両端の括弧の種類を()から[]に置換
実際に計算する順序を考えるとイメージしやすいと思いますが、この数式は三層からなる階層となっています。
第一層の部分を赤字で、第二層の部分を青字で、第三層の部分を緑字で表すと
a = ( ( 1000 + 100 ) * 10 / 2 + ( 200 + ( 10 + 30 ) / 2 ) * 100 ) + ( 3 + 5 ) * 20
となります。
置換の対象となる括弧は入れ子の階層によって区別されなければなりませんが、正規表現の手法だけでは今回のケースのような階層で区別された記号に対応することはできない場合がほとんどです。
このような入れ子構造の文字列の抽出には構文分析とよばれるアルゴリズムが実装されたプログラムを使って、括弧の階層を判別して置換する必要があります。
最後に
正規表現は非常に奥が深い上に、どんなレイヤーの技術に携わる人でも役に立つテクニックです。
他にも様々なテクニックがありますので、興味のある人は調べてみてください。